The Reasoning Revolution: How the Latest AI Advancements Are Reshaping Text-to-SQL
For years, the story of Natural Language to SQL was a story of language models getting better at guessing. Given a schema and a question, a model would generate SQL by pattern-matching against its training data — a sophisticated autocomplete with a SQL dialect baked in.
That era is ending.
The AI advancements of 2025 and 2026 — reasoning models, agentic multi-agent systems, reinforcement learning from verifiable rewards — are not incremental improvements to the same paradigm. They represent a fundamental shift in how machines turn human questions into database queries. And for anyone building or deploying NL2SQL systems, understanding this shift is no longer optional.
The Benchmark Moment
In June 2026, Google Research unveiled Gemini-SQL2, a text-to-SQL system built on Gemini 3.1 Pro that scored 80.04% execution accuracy on the BIRD benchmark — the largest standard dataset for evaluating real-world NL2SQL systems (The Decoder, 2026). By comparison, OpenAI’s GPT-5.5-xhigh scored approximately 72.8%, and Anthropic’s Claude Opus 4.6 landed at around 70.9%. Every other major provider — Databricks, AWS, Tencent, Alibaba — trailed further behind.
A seven-point gap between first and second place is not noise. In a field where marginal benchmark wins have dominated announcements for years, this is a signal worth examining carefully.
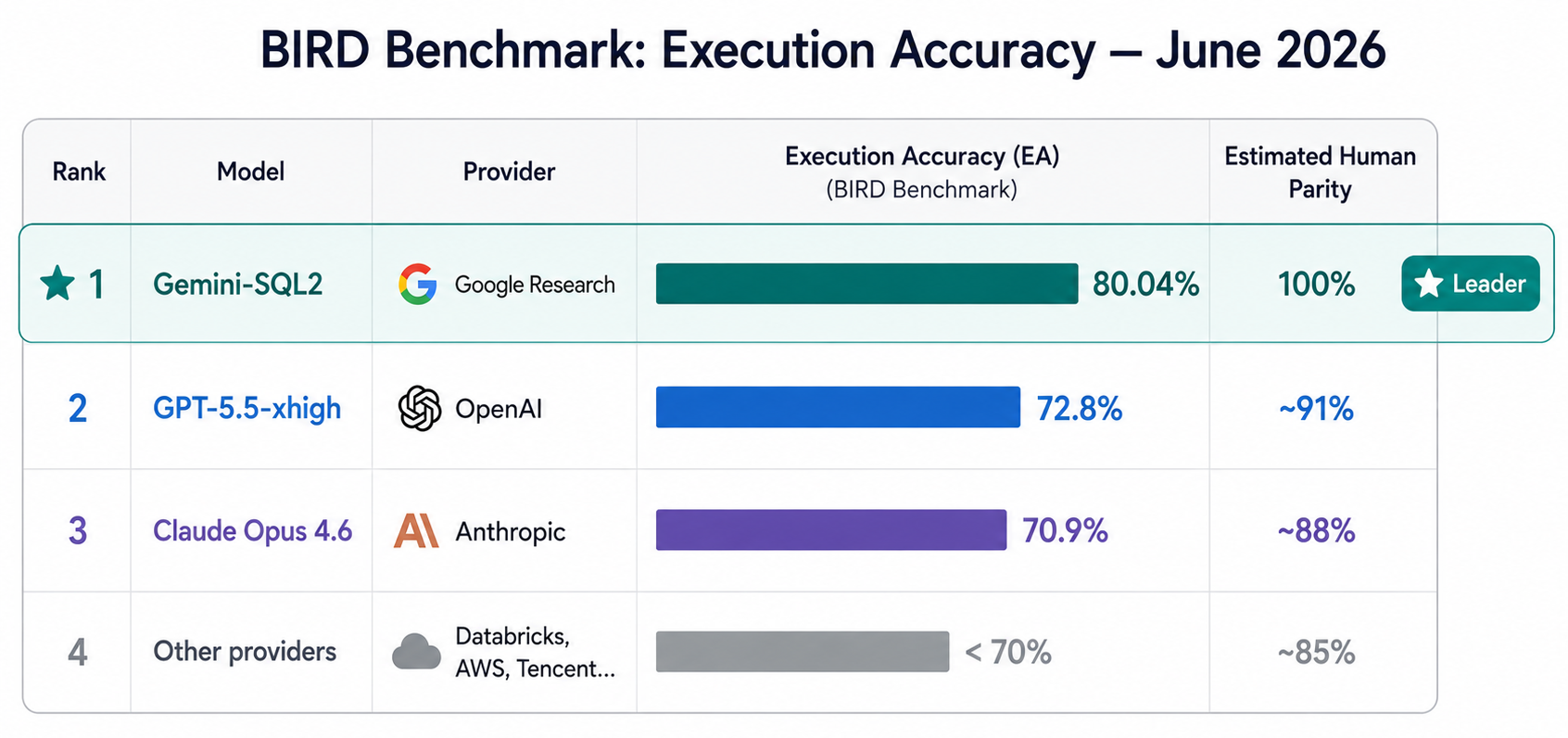
Execution accuracy (EA): percentage of generated queries returning the correct result set on the BIRD benchmark. Single-model leaderboard, June 2026.
But the more important story is not who’s winning the leaderboard. It’s why these numbers are climbing — and what the underlying architectural shifts mean for production deployments.
From Language Models to Reasoning Engines
The central innovation driving NL2SQL improvements in 2026 is the rise of reasoning models: systems trained not just to predict the next token, but to generate and evaluate intermediate reasoning steps before producing an answer.
This might sound abstract. In practice, it changes everything about how SQL gets generated.
A traditional language model approaches a query like “Show me the top five regions by revenue growth compared to the same quarter last year” by generating SQL token-by-token, guided by pattern matching against its training data. If the schema uses unusual column names or has a complex relational structure, the model guesses — and often guesses wrong.
A reasoning model approaches the same query by decomposing it: What time window is implied? What tables contain the relevant metrics? What JOIN structure is required? How should growth be calculated — absolute or percentage? Only after working through these sub-problems does it generate SQL.
Research from the BIRD benchmark team confirms this directly: among the top-performing systems on challenging evaluation sets, all the highest-scoring models are reasoning-based (BIRD-bench.github.io, 2025). Not coincidentally, the most persistent failures in non-reasoning systems — semantic aggregation errors, misidentified metrics, incorrect GROUP BY logic — are precisely the problems that structured intermediate reasoning addresses.
The Agentic Turn
Alongside reasoning models, the second major architectural shift is the move from single-pass SQL generation to agentic, multi-agent pipelines.
Where a monolithic model generates SQL in one forward pass, an agentic system distributes the work across specialized components that operate in a continuous loop:
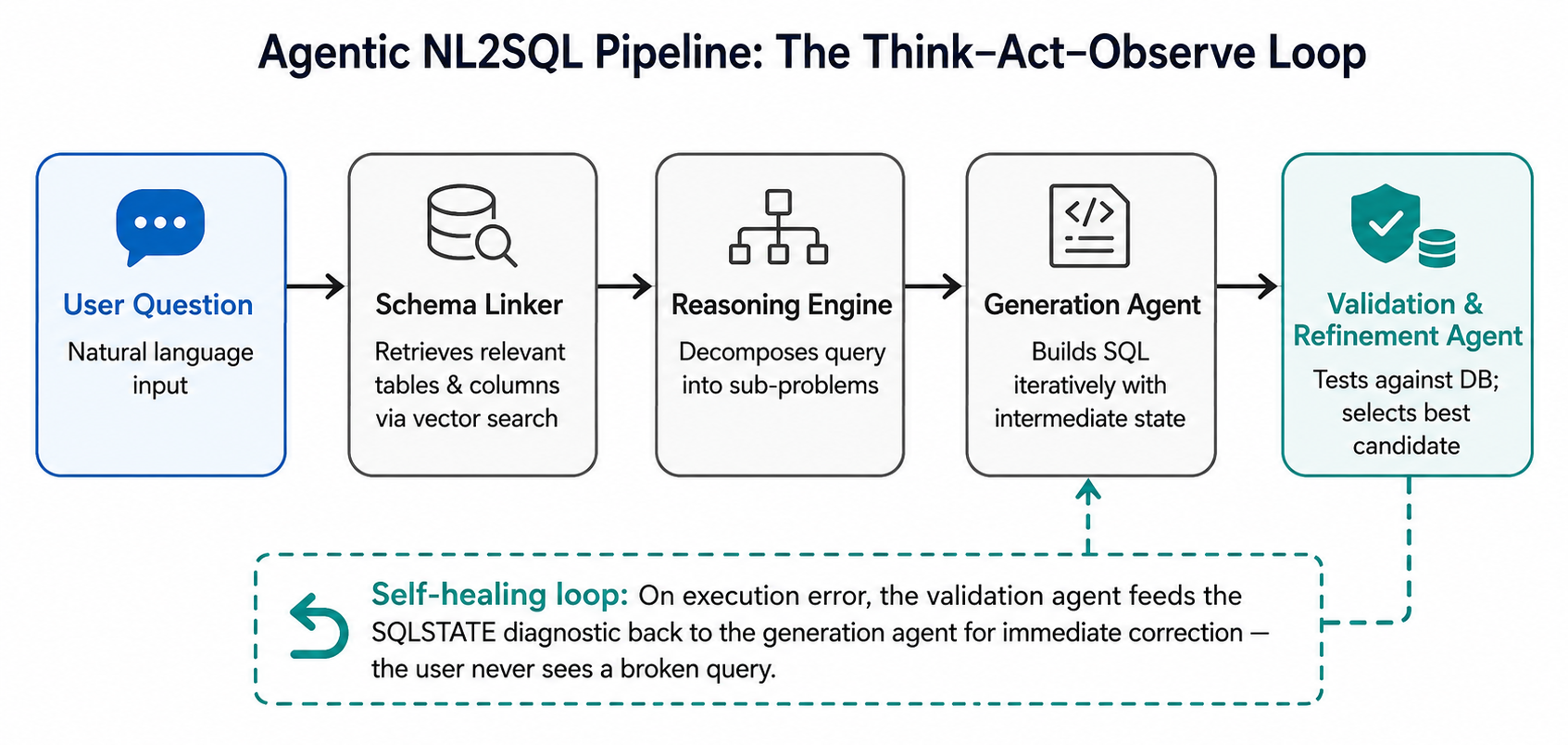
- A Schema Linking Agent that identifies which tables and columns are relevant to the user’s question via vector-based retrieval — keeping model attention focused and token usage predictable.
- A Generation Agent that builds the SQL query iteratively in a Think–Act–Observe loop, guided by intermediate state rather than generating in a single blind pass.
- A Validation & Refinement Agent that tests candidate queries against the actual database, intercepts execution errors, feeds structured diagnostic payloads back to the generator, and selects the most accurate result from multiple candidates.
Research published in late 2025 demonstrated this approach concretely. MARS-SQL, a multi-agent reinforcement learning framework, achieved 89.75% execution accuracy on Spider and 77.84% on BIRD-dev by training specialized agents for each sub-task and using a Think–Act–Observe loop for interactive SQL construction (arXiv:2511.01008). The Validation Agent alone achieved 97.15% accuracy in identifying the best candidate query — a 5-point improvement over the next-best selection strategy.
The pattern holds across multiple systems. AgentSM (January 2026) introduced semantic memory into agentic Text-to-SQL, allowing agents to reuse structured reasoning traces from prior queries rather than starting from scratch each time. The result: 25% fewer tokens used and 35% shorter reasoning trajectories on the Spider 2.0 benchmark, without sacrificing accuracy (arXiv:2601.15709). As agentic pipelines scale, this efficiency edge determines whether a system is economically viable in production — not just technically impressive in a benchmark.
The Performance Cliff — And Why It’s Getting Steeper
Here is the uncomfortable counterpoint: despite improving benchmarks, the gap between academic scores and enterprise reality is not closing at the same rate.
⚠️ Reality Check: Systems that score 85–90% on standard benchmarks routinely fall to 60% or below in actual enterprise deployments. This is not a minor discrepancy — it is a structural gap, and understanding why it exists is the precondition for closing it.
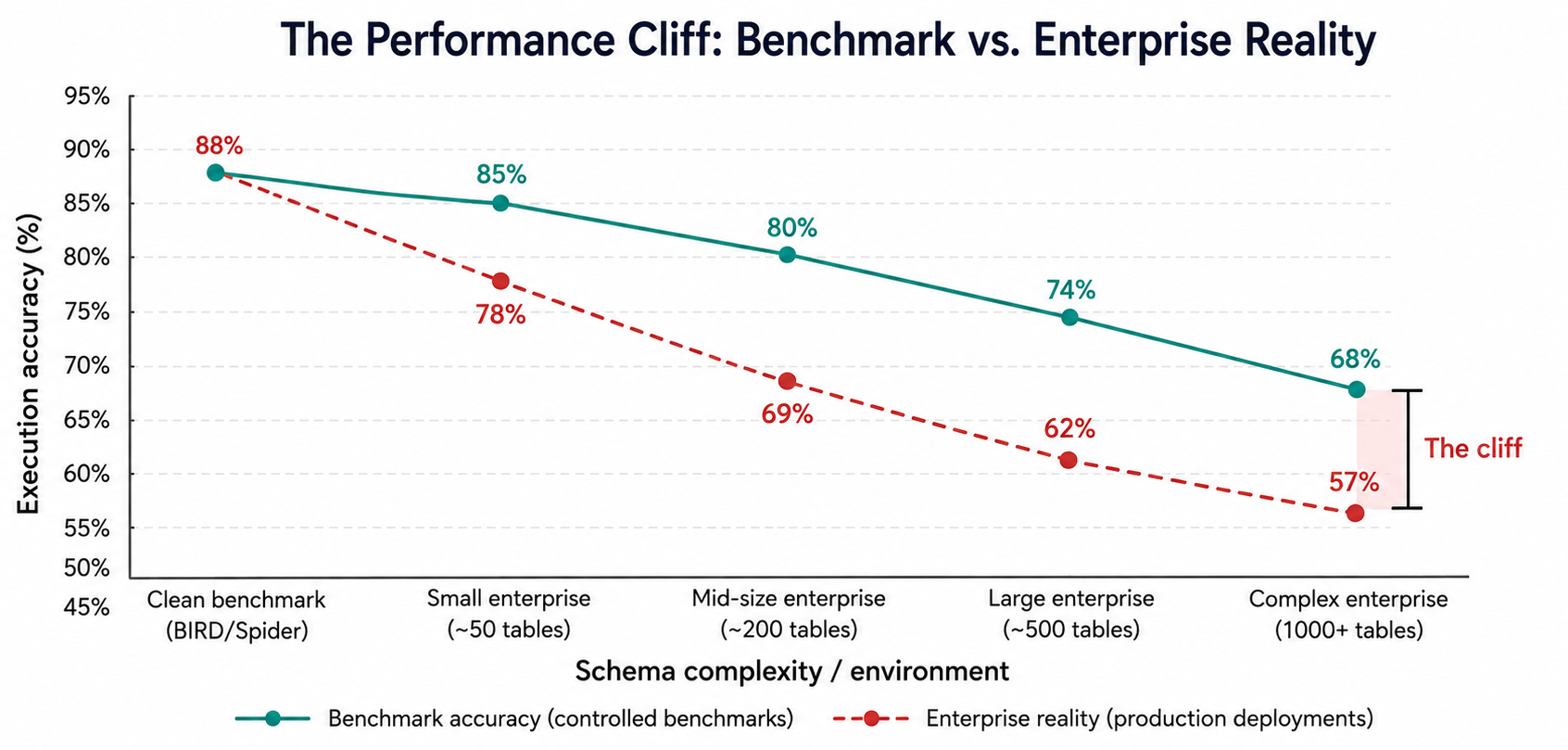
Illustrative curve based on reported benchmark scores vs. enterprise deployment findings (Mysore, 2026; CIDR 2026). The asymptotic shape reflects a real pattern: the last 10–15% of accuracy gains are exponentially harder to achieve than the first 70%, because they require resolving genuinely ambiguous business logic that no model can infer without context.
Several compounding factors drive this cliff:
Schema complexity at enterprise scale. Standard benchmarks like BIRD and Spider contain well-labeled schemas with up to a few hundred tables. Enterprise databases routinely contain thousands of tables with naming conventions that reflect years of accumulated technical debt. A model that excels at mapping “revenue” to total_sales in a clean benchmark schema will fail when the same concept is split across fact_orders, dim_transactions, and a materialized view named mv_rev_q_rollup.
This points to a prerequisite that the benchmark literature routinely understates: metadata quality is foundational. An agentic pipeline is only as good as the schema descriptions it receives. Organizations that invest in proper data catalogs, semantic layers, and well-documented column definitions will see far better real-world results than those pointing the same model at a raw, undocumented database. No reasoning architecture — however sophisticated — can compensate for the absence of a structured semantic layer describing what your data actually means.
Benchmark annotation errors. Even the benchmarks themselves are imperfect. A CIDR 2026 paper found systematic annotation errors across both BIRD and Spider 2.0, including mismatches between question semantics and intended SQL logic, and ambiguous ground-truth queries. After correcting these errors, agent rankings changed significantly — meaning reported performance gaps between systems may not reflect real-world differences accurately (Jin et al., CIDR 2026).
The semantic ambiguity problem persists. Reasoning models are better at decomposing complex questions. They are not better at resolving genuinely ambiguous business terminology. When a finance director asks for “growth,” that could mean month-over-month, year-over-year, quarter-over-prior-year-quarter, or compound annual. No amount of improved reasoning resolves ambiguity that requires human clarification.
What This Means for Production NL2SQL Systems
The AI advancements of 2026 raise the ceiling for what NL2SQL systems can achieve. They do not eliminate the fundamental requirements for building systems that work reliably outside a benchmark.
✅ Production Checklist: The architectural lessons from the research frontier, translated into requirements for systems that actually work in production:
Reasoning over generation. Systems that decompose questions into sub-problems before generating SQL consistently outperform those that generate in a single pass. This applies regardless of whether you use a frontier proprietary model or a self-hosted open-weight model — the reasoning architecture matters as much as the base model.
Validation is non-negotiable. The multi-agent systems performing best in 2026 all include dedicated validation steps: testing candidate SQL against the actual database, catching errors, and iterating. This is the research-validated equivalent of what production engineers have known empirically: you cannot ship AI-generated SQL without an execution feedback loop.
Invest in your semantic layer before your model. Vector-based schema linking retrieves only the relevant tables and columns rather than passing entire schemas into context — and it only works as well as the metadata it indexes (Piao, 2026). A well-maintained data catalog, with descriptions for every table and column, is the highest-leverage investment an organization can make in NL2SQL reliability. Agents that can read “revenue_after_refunds: net revenue in USD after deducting all customer refunds in the reporting period” will outperform agents reading rev_ar every time.
Human-in-the-loop is a feature, not a fallback. The ultimate validator for ambiguous business queries is the domain expert, not the model. The best production NL2SQL systems of 2026 know when to ask — presenting structured clarification questions when intent is ambiguous, rather than silently generating plausible-but-wrong SQL. The finance director who gets asked “Do you mean revenue growth year-over-year or quarter-over-prior-year-quarter?” will trust the system far more than one that confidently returns the wrong number. HITL is not a workaround for model limitations; it is a design principle for building systems that earn trust over time.
Efficiency gains matter for deployment. AgentSM’s 25–35% reduction in token usage points toward a real architectural imperative: as agentic pipelines become more sophisticated, they must also become more efficient. Semantic memory, intelligent pruning, and focused context management are not luxuries — they determine whether a production system is economically viable.
Self-hosted architectures preserve control. All the reasoning and agentic improvements described above are available in open-weight models. Qwen2.5-Coder (14B) and Gemma 3 (27B) both demonstrate competitive performance on BIRD and Spider in zero-shot and multi-agent configurations without sending data to external APIs (BAPPA, arXiv:2511.04153). For organizations with governance or compliance requirements, this matters: the frontier is no longer confined to closed-source providers.
Where the Field Is Heading
The trajectory from here is reasonably clear, even if the timelines are not.
Reasoning-first fine-tuning will become standard. Reinforcement learning from verifiable rewards (RLVR) — training models using execution correctness as a reward signal — has already produced state-of-the-art SQL reasoning models (Ali et al., arXiv:2509.21459). Expect this approach to proliferate across both proprietary and open-weight models over the next 12–18 months, progressively raising the floor for baseline NL2SQL accuracy.
Interactive clarification will emerge as a competitive differentiator. The systems that will matter most in production are those that know when not to guess. As base accuracy climbs, the remaining errors cluster around genuinely ambiguous questions. Systems that engage users in structured clarification — rather than silently generating plausible-but-wrong SQL — will capture the trust that raw benchmark scores cannot.
The benchmark problem will force better evaluation frameworks. The discovery of systematic annotation errors in BIRD and Spider 2.0 has accelerated work on evaluation frameworks that test production-representative scenarios: enterprise-scale schemas, multi-dialect SQL, ambiguous questions, and real business logic. BIRD-Critic (March 2026) and Spider 2.0 represent early steps in this direction. Better evaluation will produce better systems.
Self-hosted pipelines will close the accuracy gap. The 2026 data already shows open-weight models in multi-agent configurations approaching proprietary frontier performance. As model quality continues to improve and agentic infrastructure matures, the operational advantages of self-hosted deployments — data sovereignty, version control, latency, cost predictability — will be achievable without meaningful accuracy sacrifices.
The right response to an 80% benchmark result is not celebration. It is a precise question: What happens in the other 20%? For production systems, that question is the whole game.
The SQL that gets generated from a user’s question in 2026 is, on average, more accurate than it was in 2024. The AI advancements driving benchmark improvements — reasoning architectures, multi-agent pipelines, RLVR fine-tuning — are genuinely transformative. But benchmarks are controlled environments. Enterprise databases are not.
The organizations that will use NL2SQL most effectively in 2026 and beyond are those that understand both what the new reasoning models make possible, and what no model — however well-reasoned — can do alone: resolve genuinely ambiguous business questions without the right metadata, the right validation loops, and at key moments, the right human in the loop.
References
- Ali, A., et al. (2025). A State-of-the-Art SQL Reasoning Model using RLVR. arXiv:2509.21459.
- Biswal, A., et al. (2026, January 22). AgentSM: Semantic Memory for Agentic Text-to-SQL. arXiv:2601.15709.
- BIRD-bench. (2025). BIRD-Critic and benchmark updates. bird-bench.github.io.
- Jin, et al. (2026). Text-to-SQL Benchmarks are Broken: An In-Depth Analysis of Annotation Errors. CIDR 2026.
- Mysore, V. (2026, March 4). The Text-to-SQL Performance Cliff (2026): Why “Natural Language to SQL” Breaks. Medium.
- Piao, S. (2026). LitE-SQL: A Lightweight and Efficient Text-to-SQL Framework with Vector-based Schema Linking and Execution-Guided Self-Correction. Findings of EACL 2026, 3594–3601.
- The Decoder. (2026, June 13). Google Research’s Gemini-SQL2 tops text-to-SQL benchmarks by a wide margin. the-decoder.com.
- Wang, Y., et al. (2025). MARS-SQL: A Multi-Agent Reinforcement Learning Framework for Text-to-SQL. arXiv:2511.01008.
- Wu, et al. (2025). BAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL Generation. arXiv:2511.04153.